前文 动态内存管理 中描述
过,Nginx 的 slab allcator 基本上相当于为了进行共享内存的管理而开发的一个近似
通用的内存管理器。本文将要详细分析一下 slab allocator 的创建、内存申请和释放
的实现过程。
slab allocator 代码中用了相当多的位操作,很大一部分操作和 slab allocator 的
分级相关。从 2^3 bytes开始,到 pagesize/2 bytes 为止,提供 2^3, 2^4,
2^5, ..., 2^(ngx_pagesize_shift - 1) 等 ngx_pagesize_shift - 3 个内存片段
大小等级。
在分配时、Nginx 的 slab allocator 使用 BEST FIT 策略, 从和申请的内存块大小
最接近的 slot 中分配一个 chunk。同时,一个 slab 大小为了个页内存块大小
(通过 getpagesize 调用获得,一般为 4K)。
这种分级机制,会造成部分内存浪费 (internal fragmentation),但是大大降低了管理的 复杂性,代码实现起来也比较简单。也算是一种典型的拿空间换时间的样例了。
为了方便叙述,我们将
-
用于表示内存大小分级的
ngx_slab_pool_t称为 slot。整个分级区域称为 slots 数组。 -
用于实际内存分配的 pagesize 大小的内存块称为 slab。整个可用内存块区域称为 slab 数组。
-
用于管理
slab的ngx_slab_pool_t称为slab管理结构体。整个管理结构 体区域称为slab管理结构体数组。 -
从
slab从切分出来的用于完于内存请求的内存块称为 chunk。用于跟踪整个slab中chunk的使用情况的结构称为 bitmap。 -
slot的分级是按照 2 的幂次方来的,而用来计算 2 的幂次方时,移位操作又是最给 力的。我们将每个slot对应的幂值称为shift,那么这个slot能够分配的chunk大小就是1 << shift。这个slot申请来的slab可以切分出1 << (ngx_pagesize_shift - shift)个chunk。
位操作
在分析真正开始代码分析之前,先来分析一下 slab allocator 用到的主要的几个位操
作。
-
2 ^ pool->min_shift是slab allocator能够分配的最小级别chunk大小。其 它级别的内存块按倍增加 (*2),相当于1 << (min_shift++)。pool->min_size = 1 << pool->min_shift; -
slots元素个数,即slab allocator的分级。 各分级对应的shift允许值区间 是[pool->min_shift, ngx_pagesize_shift - 1],也就是说,slab allocator总共 分了ngx_pagesize_shift - pool->min_shift个级。n = ngx_pagesize_shift - pool->min_shift; -
slab allocator的最大级别chunk大小是pagesize的1/2,由全局变量ngx_slab_max_size表示。在 32 位系统pagesize为4K的环境下,ngx_slab_max_size值是2K。ngx_slab_max_size = ngx_pagesize / 2; -
一个
uintptr_t类型的变量作为bitmap来使用时,可以用来跟踪8 * sizeof(uintptr_t)个chunk的使用状态。“刚刚好” 可以用一个uintptr_t空间的bitmap能够跟踪一个slab中所有的chunk时,chunk的大小就是ngx_slab_exact_size,它所属slot的shift值就是ngx_slab_exact_shift。 在 32位系统、pagesize为4K的环境下,ngx_slab_exact_size值为128B,ngx_slab_exact_shift值为 7。ngx_slab_exact_size = ngx_pagesize / (8 * sizeof(uintptr_t)); for (n = ngx_slab_exact_size; n >>= 1; ngx_slab_exact_shift++); -
从
slab allocator中申请size大小的内存,根据 "BEST FIT" 策略,先要找到chunk大小和size最接近的slot。 前两行找到>= size的最小2 ^ shift的数,由于最小级别shift是pool->min_shift,那shift - pool->min_shift就 得到了对应slot在slots中的偏移。shift = 1; for (s = size - 1; s >>= 1; shift++); slot = shift - pool->min_shift; -
page指向刚刚申请到的一个slab的管理结构体,其在管理结构体数组里的位置就 是page - pool->pages。slab管理结构和slab又是一一对应的,那么slab在slab数组中的偏移也是page - pool->pages。一个slab大小是1 << ngx_pagesize_shift,那么就可以计算出slab的相对地址了。p = (page - pool->pages) << ngx_pagesize_shift; p += (uintptr_t) pool->start; -
从
shift对应的slot申请的chunk大小是1 << shift。1 << (ngx_pagesize_shift - shift)又是此slot中一个slab可以切分出的chunk个数,一个chunk需要一个bit来跟踪使用状态,那么就需要map个uintptr_t来存储跟踪一个slab中chunk使用状态的bitmap了。map = (1 << (ngx_pagesize_shift - shift)) / (sizeof(uintptr_t) * 8); -
在
shift > ngx_slab_exact_shift情况下,slab allocator使用page->slab的高16位存储bitmap,低 4 位存储slab所属slot的shift值。所以,第二 行的n值含义是此slot的slab可以切分出多少个chunk。一个chunk状态 又需占用bitmap中的一个bit,在bitmap全满时的状态就是(1 << n) - 1。n = ngx_pagesize_shift - (page->slab & NGX_SLAB_SHIFT_MASK); n = 1 << n; n = ((uintptr_t) 1 << n) - 1; mask = n << NGX_SLAB_MAP_SHIFT; -
在
shift < ngx_slab_exact_shift情况下,由于一个uintptr_t大小的bitmap无法跟踪所有chunk状态,slab allocator直接占用n个chunk存储bitmap。这n个chunk需要在bitmap中置为己使用状态。同时,这段代码紧接 着的逻辑还需要返回给调用者一个chunk,故这个即将被使用的chunk也需要被置为 己使用状态。s = 1 << shift; n = (1 << (ngx_pagesize_shift - shift)) / 8 /s; bitmap[0] = (2 << n) - 1; -
slab的chunk个数除于一个uintptr_t类型包含的bit数,得到这个bitmap需要占用个uintptr_t的连续空间。map = (1 << (ngx_pagesize_shift - shift)) / (sizeof(uintptr_t) * 8); -
因为结构体对齐的原因,
ngx_slab_pool_t和ngx_slab_page_t在 32 位系统中都 是按 4 字节对齐 (4-byte aligned),同时共享内存起始地址至少是 4 字节对齐的。所以&slots[slot]的值低2位是0,可用以用存储额外信息。page->prev = (uintptr_t) &slots[slot] | NGX_SLAB_SMALL; page->prev = (uintptr_t) &slots[slot] | NGX_SLAB_EXACT; page->prev = (uintptr_t) &slots[slot] | NGX_SLAB_BIG; prev = (ngx_slab_page_t *) (page->prev & ~NGX_SLAB_PAGE_MASK); -
由将要释放的内存块指针得到它所属的
slab和slab管理结构体索引。n = ((u_char *) p - pool->start) >> ngx_pagesize_shift; page = &pool->pages[n];
基本类型
-
操作系统级共享内存块表示
--------os/unix/ngx_shmem.h:15------ typedef struct { u_char *addr; /* 共享内存块的起始地址 */ size_t size; /* 共享内存块的大小 */ ngx_str_t name; ngx_log_t *log; ngx_uint_t exists; } ngx_shm_t; -
Nginx 内部的共享内存块表示
-------core/ngx_cycle.h:28---------- struct ngx_shm_zone_s { void *data; /* 存储模块相关数据,与内存分配无关 */ ngx_shm_t shm; /* shm.addr 转换成 ngx_slab_pool_t 使用 */ ngx_shm_zone_init_pt init; /* 模块相关的初始化函数。比如,从 slab_pool中申请内存,给 data 字 段赋值等 */ void *tag; /* 共享内存块的所有者 */ }; typedef struct ngx_shm_zone_s ngx_shm_zone_t; -
slab 管理结构体
------------core/ngx_slab.h:17---------- struct ngx_slab_page_s { uintptr_t slab; /* 不同场景下用于:存储 bitmap、shift 值、 或者后续连续的空闲 slab 个数*/ ngx_slab_page_t *next; uintptr_t prev; /* 双链表的前向指针,同时存储 `slab` 属性信 息 */ }; typedef struct ngx_slab_page_s ngx_slab_page_t; -
slab allocator主结构体------------core/ngx_slab.h:24---------- typedef struct { ... size_t min_size; /* 最小 chunk 字节数 */ size_t min_shift; /* 最小 chunk 字节数是 2 的多少次幂 */ ngx_slab_page_t *pages; /* slab 的管理结构体数组首地址 */ ngx_slab_page_t free; /* 空闲的 slab 管理结构体链表 */ u_char *start; /* pagesize align'ed,slab 数组起始地址 */ u_char *end; /* 整个共享内存块结束地址 */ ... void *data; /* 用户数据 */ void *addr; /* 整个共享内存块起始地址 */ } ngx_slab_pool_t;
共享内存操作
下面的分析暂不考虑大内存块 (大小大于等于 ngx_slab_max_size) 的内存块申请和释放,
对它们的操作比较简单,不涉及到 slot 分级机制、bitmap 等逻辑。
初始化
Nginx 初始化完成后,各模块通过自己申请的内存块对应的ngx_shm_zone_t管理内存,
ngx_slab_pool_t并不直接暴露在外,而是被间接转换后使用:
-------http/modules/ngx_http_limit_req_module.c:494-------
static ngx_int_t
ngx_http_limit_req_init_zone(ngx_shm_zone_t *shm_zone, void *data)
{
ctx->shmpool = (ngx_slab_pool_t *) shm_zone->shm.addr;
ctx->sh = ngx_slab_alloc(ctx->shmpool, sizeof(ngx_http_limit_req_shctx_t));
ctx->shmpool->data = ctx->sh;
ngx_rbtree_init(&ctx->sh->rbtree, &ctx->sh->sentinel,
ngx_http_limit_req_rbtree_insert_value);
ngx_queue_init(&ctx->sh->queue);
}
slab allocator 初始化完成后,slab allocator 的状态示意图如下:
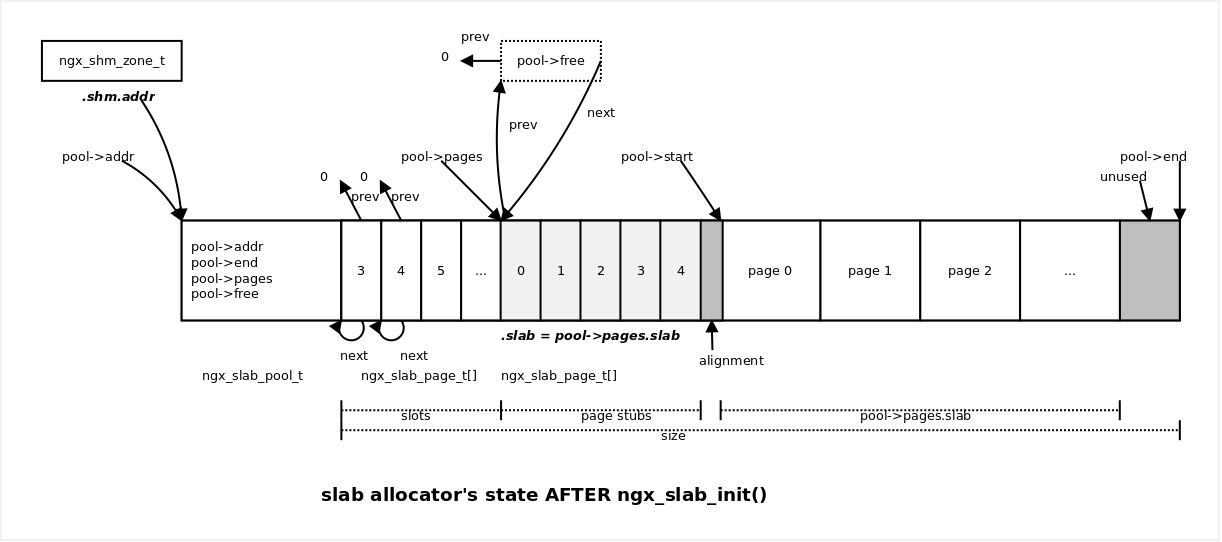
初始化过程如下:
-------core/ngx_cycle.c:881-------------
static ngx_int_t
ngx_init_zone_pool(ngx_cycle *cycle, ngx_shm_zone_t *zn)
{
sp = (ngx_slab_pool_t *)zn->shm.addr;
sp->end = zn->shm.addr + zn->shm.size;
sp->min_shift = 3;
sp->addr = zn->shm.addr;
ngx_slab_init(sp);
}
-------core/ngx_slab.c:76---------------
void
ngx_slab_init(ngx_slab_pool_t *pool)
{
...
pool->min_size = 1 << pool->min_shift;
p = (u_char *) pool + sizeof(ngx_slab_pool_t);
size = pool->end - p;
ngx_slab_junk(p, size);
...
slots = (ngx_slab_page_t *)p;
n = ngx_page_size_shift - poo->min_shift;
for (i = 0; i < n; i++) {
slots[i].slab = 0;
slots[i].next = &slots[i];
slots[i].prev = 0;
}
p += n * sizeof(ngx_slab_page_t);
pages = (ngx_uint_t) (size / (ngx_pagesize + sizeof(ngx_slab_page_t)));
ngx_memzero(p, pages * sizeof(ngx_slab_page_t));
pool->pages = (ngx_slab_page_t *) p;
pool->free.prev = 0;
pool->free.next = (ngx_slab_page_t *) p;
pool->pages->slab = pages;
pool->pages->next = &pool->free;
pool->pages->prev = (uintptr_t) &pool->free;
pool->start = (u_char *)
ngx_align_ptr((uintptr_t) p + pages * sizeof(ngx_slab_page_t),
ngx_pagesize);
m = pages - (pool->end - pool->start) / ngx_pagesize;
if (m > 0) {
pages -= m;
pool->pages->slab = pages;
}
...
}
对上面代码的补充说明:
-
每个
slot都是一个ngx_slab_pool_t链表,初始链表只有一个元素,ngx_slab_page_t.next指向自己。 -
每个
slab管理结构都和一个slab一一对应。整个共享内存可以有(size / (ngx_pagesize + sizeof(ngx_slab_page_t)))个slab。 -
slots占用空间也参与了pages值的计算 (包含在size里),然后再根据实际可 分配的slab个数 (按pagesizealigned),再次修正pages值。个人感觉没看懂, 虽然关系不大,但是如果在第一次计算pages的时候使用了正确的size,那pages就会变小,在对slab进行对齐时,很可能可以多挤出一个slab的空间。 -
初始化完
pool->pages和pool->free后,按照实际可用的slab(因为slab起始地址需要按pagesize对齐),调整pool->pages->slab值。m = pages - available_pages; if (m > 0) { pool->pages->slab = available_pages; } -
slot指向尚有空闲的slab管理结构组成的双向链表。已经完全用尽的slab会 处于游离状态,直到其上有chunk被释放后,slab管理结构才再次被加到双向链表的 头部。
内存申请
内存分配主要由函数 ngx_slab_alloc_locked 完成,在分配开始时,先根据申请的内存
块大小 size 定位到需要使用的 slot (如果 size 大于 ngx_slab_max_size 的
话,直接从 slab 数组中申请整块或者连续多块 slab 返回给申请者)。
if (size > pool->min_size) {
shift = 1;
for (s = size - 1; s >> 1; shift++) { /* void */ }
slot = shift - pool->min_shift;
} else {
size = pool->min_size;
shift = pool->min_shift;
slot = 0;
}
对上述代码的几点补充说明:
-
slab allocator能分配的最小chunk大小为pool->min_size,所有小于此大小 的内存申请请求,都按pool->min_size分配。其对应的slot是slots[0]。 -
大于
pool->min_size的内存申请请求,根据 BEST FIT 策略,找到略微大于或等 于size的slot,从中再申请chunk。
从 slot 中分配 chunk
根据 bitmap 的存储位置,slot 又分为三个类别:
-
slot对应的shift小于ngx_slab_exact_shift的,bitmap存储于slab中的前几个chunk中。 -
slot对应的shift等于ngx_slab_exact_shift的,bitmap存储于ngx_slab_page_t的.slab成员中。 -
slot对就的shift大于ngx_slab_exact_shift的,bitmap存储于ngx_slab_page_t的.slab成员的高位中。
不管是哪一类 slot,chunk 分配的基本流程都是:
- 找到
bitmap - 从
bitmap中定位到第一个空闲的chunk - 将
chunk在bitmap中的对应位置 1 - 如果,
chunk所在的slab已经不再有空闲chunk,将此slab对应的管理结构 体从slot链表中摘除 - 返回
chunk给申请者
篇幅起见 (已经很长了好不?),只对第一类 slot 的分配代码作详细分析,同时,
-
这段代码在
slot链表中存在有空闲slab(slots[slot].next != &slots[slot]) 的前提下才会被执行。 -
在
slot为空时 ,会直接执行下一章节 (slab 申请) 的代码。
按照上面总结的分配流程,首先需要定位 slab 的 bitmap。对于 shift 小于
ngx_slab_exact_shift 的 slot,slab 的 bitmap 存储于前几个 chunk 中。
--------core/ngx_slab.c:203---------------
p = (page - pool->pages) << ngx_pagesize_shift;
bitmap = (uintptr_t *) (pool->start + p);
map = (1 << (ngx_pagesize_shift - shift)) / (sizeof(uintptr_t) * 8);
对上面代码的几点补充说明:
map> 1, 并且bitmap占用多个完整的uintptr_t类型空间。/* 其中 n 为 sizeof(uintptr_t) 的 2 的幂值, 且 shift < ngx_slab_exact_shift */ ngx_slab_exact_shift = ngx_pagesize_shift - (n + 3) 2 ^ (ngx_pagesize_shift - shift) / (2 ^ n * 2 ^ 3) = 2 ^ (ngx_pagesize_shift - shift - (n + 3)) > 2 ^ 0 = 1
接下来,从 bitmap 中定位第一个空闲的 chunk。由于 bitmap 是按照连续的
uintptr_t 存储的,所以可以先按 uintptr_t 为基本单位,找到存在空闲位的
uintptr_t,然后再从 uintptr_t 中定位到具体空闲的位。
----------core/ngx_slab.c:209---------
for (n = 0; n < map; n++) {
if (bitmap[n] != NGX_SLAB_BUSY) {
for (m = 1, i = 0; m; m <<= 1, i++) {
if (bitmap[n] & m)) {
continue;
}
...
再接下来,将 chunk 对应位在 bitmap 中置 1,再检查此 slab 是否已经完全被
分配完毕。其中,i 为空闲 chunk 空闲对应 bit 在 uintptr_t 中的序号,n
为 uintptr_t 在 bitmap 中的序号。
-----------core/ngx_slab.c:218---------
bitmap[n] |= m;
i = ((n * sizeof(uintptr_t) * 8) << shift) + (i << shift);
if (bitmap[n] == NGX_SLAB_BUSY) {
for (n = n + 1; n < map; n++) {
if (bitmap[n] != NGX_SLAB_BUSY) {
p = (uintptr_t) bitmap + i;
goto done;
}
}
prev = (ngx_slab_page_t *) (page->prev & ~NGX_SLAB_PAGE_MASK);
prev->next = page->next;
page->next->prev = page->prev;
page->next = NULL;
page->prev = NGX_SLAB_SMALL;
}
p = (uintptr_t) bitmap + i;
goto done;
对上述代码的几点说明:
(n * sizeof(uintptr_t) * 8) << shift等于(n * sizeof(uintptr_t) * 8) * 1 << shift,1 << shift是一个chunk大小,那 整个表达式的结果就是n个uintptr_t表示的chunk地址范围。那么再加上i << shift就得到了第n * sizeof(uintptr_t) * 8 + i个bit位对应的chunk起始地址。
slab 申请
如果 slot 链表中没有可分配 chunk 时,slab allocator 调用
ngx_slab_alloc_pages 从 slab 数组中申请一个新的 slab,按照 slot 对应级别
进行切分后,再从中拿到第一个空闲 chunk 返回给客户端。
pool->free 空闲 slab 对应管理结构组成的双向链表的头节点,它本身并不对应任何
slab。它的作用相当于一个 sentinel。
-------------core/ngx_slab.c:625--------
for (page = pool->free.next; page != &pool->free; page = page->next) {
...
}
同时,需要注意的就是,双向链表中的节点,有可能并不只对应一个 slab。其
ngx_slab_page_t.slab 字段的值就表示此 slab 管理结构对应 slab 后面连续
ngx_slab_page_t.slab -1 个 slab 都由此 slab 管理结构负责跟踪。
slab allocator 之所以这么做,是为了满足那些超过一个 slab 大小的内存请求。
在 slab allocator 初始化完成之后,pool->free 指向的空闲 slab 双向链表里只
有一个 slab 管理结构节点,此节点跟踪所有的 slab。
总结下来就是:
-
ngx_slab_page_t.slab成员保存此结构对应的slab后面连续可用的slab个数。 -
申请多个连续的
slab时,连续slab对应的ngx_slab_page_t(第一个除外), 都被设为NGX_SLAB_PAGE_BUSY标志,第一个ngx_slab_page_t被添加了NGX_SLAB_PAGE_START标志。 -
pool->free链表只将空闲的slab管理结构链入其中。已经分配出去 (分配给了 某个slot或者直接返回给了用户) 的slab管理结构不在此链表中。
从新 slab 中分配 chunk
这个过程和 从 slot 中分配 chunk 描述的过程类似,具体执行逻辑也和 slot
的分类相关。 不同之处在于,刚刚从 slab 数组中申请到的 slab 还未进行初始化。
下面的分析也只针对 shift 小于 ngx_slab_exact_shift 的 slot。
此类 slab 的 bitmap 存储于 slab 内存中,并且占用 slab 的头几个 chunk。
那么,首先要确定的就是此 bitmap 的起始位置,和它需要占用几个 chunk。
-----------core/ngx_slab.c:334--------------
p = (page - pool->pages) << ngx_pagesize_shift;
bitmap = (uintptr *) (pool->start + p);
s = 1 << shift;
n = (1 << (ngx_pagesize_shift - shift)) / 8 / s;
...
bitmap[0] = (2 << n) -1;
map = (1 << (ngx_pagesize_shift - shift)) / (sizeof(uintptr_t) * 8);
...
n 表示 bitmap 要占用的 chunk 个数,map 表示 bitmap 要占用的 uintptr_t
个数。
随后,将此 slab 管理结构体挂接到 slot 链表的头部 (代码如果执行到这一步,已经
说明 slot 无空闲 chunk 可用,所以此时链表为空):
------------core/ngx_slab.c:352-------------
page->slab = shift;
page->next = &slots[slot];
page->prev = (uintptr_t) &slots[slot] | NGX_SLAB_SMALL;
slots[slot].next = page;
最后,返回分配给请求者的 chunk 首地址:
------------core/ngx_slab.c:358-------------
p = ((page - pool->pages) << ngx_pagesize_shift) + s * n;
p += (uintptr_t) pool->start;
goto done;
Phew! 再上一张 slab allocator 初始化过后,刚刚分配出一个 chunk 后的状态图:
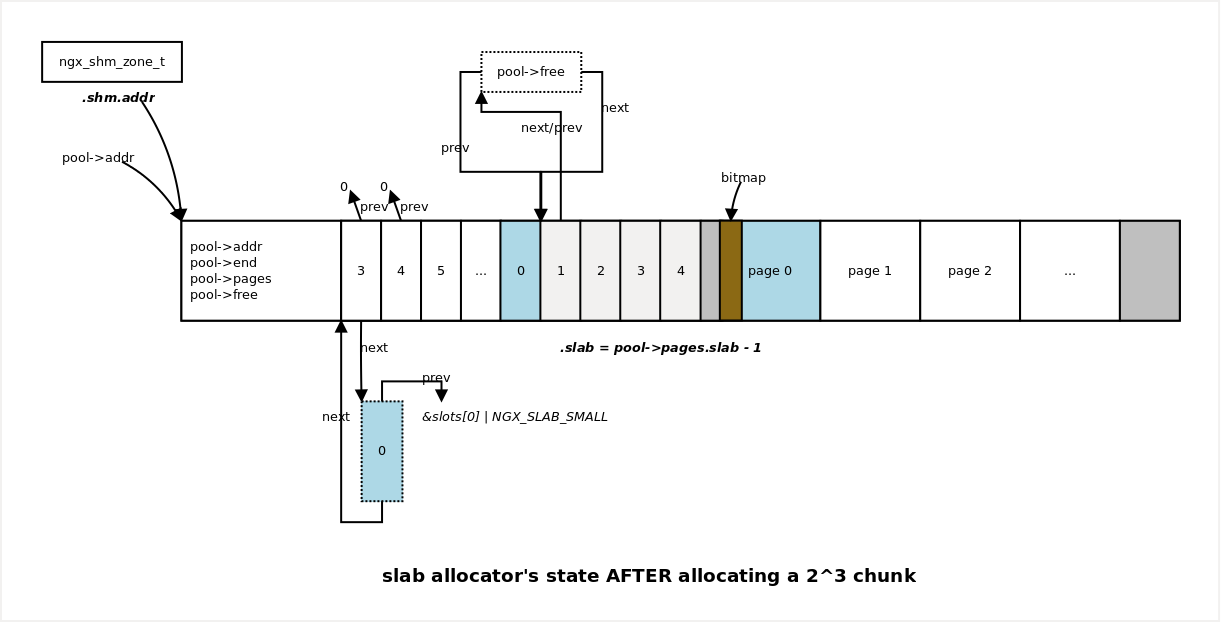
内存释放
内存释放的流程大致为:
- 校验释放的内存块
chunk地址在不在slab allocator管理范围内 - 找到
chunk所属的slab地址和类型 - 定位到
slab的bitmap - 在
bitmap中将chunk对应bit置 0 - 检查
slab是否已经完全空闲。如果完全空闲,将slab释放回slab数组,此slab可能会再次被其它slot申请使用。 - 如果释放的
chunk是slab第一块空闲块,将slab加入slot链表头部
篇幅起见,只对第一类 slot 的释放代码作详细分析。
对 chunk 地址的检验,一方面验证一下此地址是否在 slab allocator 的地址范围内。
另外一方面,校验地址是否符合 slab allocator 的规则 (地址值是 chunk 大小的倍
数):
---------------core/ngx_slab.c:422------------
if ((u_char *) p < pool->start || (u_char *) p > pool->end) {
...
}
---------------core/ngx_slab.c:439------------
if ((uintptr_t) p & (size - 1)) {
...
}
然后,定位地址所在的 slab 地址和类型:
--------------core/ngx_slab.c:427-------------
n = ((u_char *) p - pool->start) >> ngx_pagesize_shift;
page = &pool->pages[n];
slab = page->slab;
type = page->prev & NGX_SLAB_PAGE_MASK;
对上述代码补充说明的几点:
slab起始地址在初始化时都按ngx_pagesize对齐过,所以它的值是ngx_pagesize的倍数。
我们只考虑第一类 slot,它的 type 是 NGX_SLAB_SMALL。下面再找到 bitmap 的
位置和大小:
-------------core/ngx_slab.c:443--------------
n = ((uintptr_t) p & (ngx_pagesize - 1)) >> shift;
m = (uintptr_t) 1 << (n & (sizeof(uintptr_t) * 8 - 1));
n /= (sizeof(uintptr) * 8);
bitmap = (uintptr_t *) ((uintptr_t) p & ~(ngx_pagesize - 1));
对上述代码的几点补充:
-
n值为p指向的chunk在slab中的索引。p & (ngx_pagesize - 1)计算 出来了chunk相对于slab起始地址的相对地址。因为可以chunk索引n乘于chunk块大小1 << shift得到chunk相对于slab起始地址的相对地址,反过 来就能得到n值。 -
m值是n值在一个uintptr_t对应位置1的 mask 值。n & (sizeof(uintptr_t) * 8 - 1)相当于n % ((sizeof(uintptr) * 8)
后续的其它操作就不在分析了,基本操作和申请时大同小异。
最后
写得不好,多多包涵。写一篇文章,没想像中的轻松,写出的文字也没想像中的易懂。 但是,发现一个字一个字敲出来后,真的比之前理解的更深刻了一点。
希望我能继续下去吧。
Comments
不要轻轻地离开我,请留下点什么...